
The Malaga Film Festival, in collaboration with Festhome, opens the call for submissions for the 2nd edition of the Ibershorts Award.


Málaga Film Festival opens the call for entries for the second edition of the Ibershorts Award
Nearly 30 festivals from 20 countries will take part in the festival’s 30th edition through this initiative, in collaboration with Festhome
The Málaga Film Festival, organized by Málaga City Council through Málaga Procultura, has opened the call for entries for the second edition of the Ibershorts Award, which will take place during the festival’s 30th edition, to be held from February 26 to March 7, 2027. The complete rules and regulations are available on the Festival’s website, and submissions must be made through the Festhome platform until November 30, 2026.
Ibershorts is an initiative created by the Málaga Film Festival in partnership with Festhome to promote and showcase Ibero-American fiction and animation short films. Integrated into the festival’s official program, the award aims to recognize the quality and diversity of short films produced in Ibero-American countries (including Portugal and excluding Spain).
Through this initiative, the Málaga Film Festival further strengthens its commitment to Ibero-American audiovisual creation through alliances with other festivals that have a strong dedication to short films and a significant influence within the industry. These festivals form a qualifying network aimed at fostering Ibero-American fiction and animation short films and creating new opportunities for their filmmakers.
A total of 29 festivals from 20 countries are taking part in this edition. Each participating festival may submit up to two award-winning short films from its most recent edition (the Jury Award winner and the Audience Award winner, or their equivalent). These films will automatically become eligible alongside winners from the other participating festivals. A joint committee appointed by the Málaga Film Festival and Festhome will select five finalists, which will be screened during the 30th Málaga Film Festival.
The winner of the Ibershorts Award will receive the Biznaga for Best Ibero-American Fiction Short Film. The award will be presented during the Málaga Film Festival Short Film Awards Ceremony. In addition, the five selected short films will become part of the Málaga Short Corner, an initiative within MAFIZ / Spanish Screenings Content where, beyond the screenings, filmmakers will participate in various industry activities.
Festivals participating in the Ibershorts Award 2027
- ASUFICC - International Contemporary Film Festival of Asunción (Paraguay)
- Baixada Animada - Ibero-American Animation Film Festival (Brazil)
- BITBANG International Animation Festival (Argentina)
- Ibero-American Short Film Competition Versión Española / SGAE (Spain)
- Curtas Vila do Conde - International Film Festival (Portugal)
- Curta-SE Ibero-American Cinema Festival of Sergipe (Brazil)
- FAM - Florianópolis Audiovisual Mercosur (Brazil)
- FANTLATAM (alliance of 32 Latin American fantastic film festivals) (Argentina, Brazil, Mexico, Venezuela, Panama, Uruguay, Colombia, Peru, Costa Rica, Puerto Rico and Chile)
- FENAVID - Santa Cruz International Film Festival (Bolivia)
- Gramado Film Festival (Brazil)
- Global Film Festival Santo Domingo (Dominican Republic)
- Huelva Ibero-American Film Festival (Spain)
- Al Este International Film Festival (Peru)
- Cuenca International Film Festival - FICC (Ecuador)
- Huesca International Film Festival (Spain)
- Lebu International Film Festival (CINELEBU) (Chile)
- Mar del Plata International Film Festival (Argentina)
- Valdivia International Film Festival (Chile)
- Kinoarte Film Festival (Brazil)
- FIC UBA - International Film Festival of the University of Buenos Aires (Argentina)
- FICCI - Cartagena International Film Festival (Colombia)
- Hayah - Panama International Short Film Festival (Panama)
- Ícaro Central American International Film Festival (Guatemala, El Salvador, Honduras, Nicaragua, Costa Rica and Panama)
- José Ignacio International Film Festival (Uruguay)
- LESGAICINEMAD (Spain)
- Pávez Awards - Talavera de la Reina International Film Festival (Spain)
- Shorts Costa Rica (Costa Rica)
- Shorts México (Mexico)
- Skyline Benidorm Film Festival (Spain)
Festhome Distribution Award at Bio Bio Conecta WIP, 28th Cinelebu International Film Festival 2026

Mamífera Wins the Festhome Digital Distribution Award at Biobío Conecta (Cinelebu)!
Great news for independent and Ibero-American cinema! Regional talent continues to make its mark, and at Festhome, we could not be prouder to support and promote film projects during some of the most crucial stages of their journey.
During the 26th edition of the Lebu International Film Festival (Cinelebu), a highly prestigious event internationally recognized as an Academy Awards® qualifying festival, the Festhome Digital Distribution Award was presented within the Biobío Conecta industry section.
An Outstanding Jury for the Work In Progress (WIP)
The Work In Progress (WIP) section is a vital space where filmmakers present the current stage of their projects to international industry experts, receiving valuable feedback that contributes to their development and completion.
On this occasion, the responsibility of evaluating the projects and selecting the winner was entrusted to an exceptional jury:
- Edui Tijerina: Renowned Mexican writer, playwright, screenwriter, instructor, media analyst, educator, and audiovisual project consultant.
- Moisés Tuñón: Director of Festhome.
Together, both professionals combined their experience and expertise to assess the submitted works, highlighting the exceptionally high level of the competition.
The Winning Project: Mamífera (Chile)

Ultimately, the jury awarded the prize to the short film Mamífera, a project that completely captivated both the evaluators and the industry professionals in attendance.
- Director: Víctor Soto Castillo (filmmaker from Ovalle, Chile).
- Producer: Carolina Astudillo Avilés.
This Chilean regional production stood out thanks to its powerful visual and narrative approach. Mamífera is a sensitive and compelling portrait of life and ancestral practices in the Andes, preserving identity, territory, and cultural roots in a deeply moving way.
What Does the Award Include?

To support the future of the project and ensure that its message reaches audiences around the world, the Festhome Digital Distribution Award consists of one year of assistance and support for the film's festival distribution through the Festhome platform.
Thanks to this benefit, the team behind Mamífera will receive strategic support from our platform to manage and optimize their festival submission strategy across the international festival circuit over the next twelve months.
We are delighted to share this recognition and to accompany Víctor Soto Castillo, Carolina Astudillo, and the entire team on the promising journey that lies ahead for this remarkable project.
Congratulations!
```
Festhome Award at WIP Short Films, FICCI 46 Cartagena de Indias International Film Festival 2026

Festhome Supports Emerging Talent at #FICCI65: Bingo Night Wins the WIP Short Films Award
The Cartagena International Film Festival (FICCI) continues to strengthen its position as a vital platform for the development of new voices in Ibero-American cinema. In its 65th edition, the Work in Progress (WIP) Short Films section presented a selection of four projects currently in development, showcasing works at a decisive stage in their journey and creating space for bold cinematic explorations and innovative storytelling within contemporary filmmaking.
An Internationally Acclaimed Jury
This year's participating projects were evaluated by a distinguished international jury whose expertise and perspective play a crucial role in supporting these films on their path toward completion and circulation:
- Diandra Arriaga
- Mustafa Uzuner
- Yan Deccopet
The Winning Project: Bingo Night

Following the screening sessions and jury deliberations, the Festhome Award was presented to:
Bingo Night, directed by Maria Vaughan.
This short film, currently at a pivotal stage of its development, will receive support from our platform to strengthen its future strategy within the international festival circuit. Vaughan's work stands out for its distinctive cinematic voice and is already emerging as one of the titles to watch in the coming season.
For more information about the award-winning project, you can visit the official FICCI website.
The Commitment of Festhome to Short Films and Ibero-American Cinema

This award reaffirms Festhome's core mission: breaking down the geographical and industry barriers that independent filmmakers often face. Short films are, by nature, the creative laboratory where the future of cinema is born, yet they are also among the formats that require the most strategic support to stand out in an increasingly competitive global market.
By presenting this incentive within such a prestigious framework as FICCI, we renew our long-standing commitment to Ibero-American cinema. We believe that the final stages of a project should never become an obstacle to its visibility and circulation. Through accessible digital tools and ongoing support in festival submissions management, our goal is to remain the technical and human bridge that connects the stories of our region with screens, programmers, and audiences around the world.
Congratulations to Maria Vaughan and the entire team behind Bingo Night for this well-deserved recognition. See you on the festival circuit!
```
Festhome Award at Málaga Short Corner 2026

Festhome Awards Talent at MAFIZ: The Fable of the Teenage Punk Triumphs at the Málaga Short Corner
Through its industry area, MAFIZ (Málaga Festival Industry Zone), the Málaga Film Festival continues to establish itself as one of the most important hubs for the promotion, co-production, and distribution of Ibero-American cinema. Within this dynamic environment, the Málaga Short Corner stands out as the perfect showcase for discovering the freshest, boldest, and most promising voices in short filmmaking.
At Festhome, staying true to our commitment to supporting emerging filmmakers and streamlining their distribution journey, we were proud to present our special award at this year's edition of MAFIZ. The winning short film was the captivating and daring The Fable of the Teenage Punk, directed by Juan Vicente Castillejo.
Supporting the Film’s International Journey

The award presented by Festhome has a clear purpose: to provide the team behind The Fable of the Teenage Punk with the essential tools to expand their horizons and bring their story to audiences around the world. The prize consists of €3,000 in submission fee credits, dedicated entirely to supporting the film's participation in international film festivals.
We know that a short film's journey does not end when the editing room lights go out. In many ways, that is precisely when the real adventure begins: building a strategy, finding audiences, and connecting with new territories. Through this award, we aim to help this unique “fable” travel beyond geographical boundaries, simplifying and strengthening its future submissions through Festhome’s global network of partner festivals.
A Strategic Stop at the Málaga Short Corner

The Málaga Short Corner is much more than a screening space. It is a key meeting point where sales agents, international festival programmers, and distributors connect directly with the future of our cinema. Awarding a film in such a prestigious setting reinforces Festhome’s core mission: building meaningful bridges between emerging talent and the global film industry.
We would like to extend our warmest congratulations to Juan Vicente Castillejo and the entire creative and technical team behind The Fable of the Teenage Punk for this well-deserved recognition at MAFIZ. We are excited to follow your journey closely, support your upcoming festival submissions, and celebrate every new selection on the international circuit.
We wish you every success in the exciting journey ahead!
```
More than 15 Ibershorts Award Candidates to Participate in the Málaga Short Corner at MAFIZ

AVAILABLE TO INDUSTRY PROFESSIONALS IN A PRIVATE VIDEO LIBRARY ON FESTHOME TV
More than 15 short films nominated for the Ibershorts Awards will take part in the
Málaga Short Corner, the section dedicated to the international promotion and distribution of Spanish short films within MAFIZ, the industry area of the Festival de Málaga.
Through Málaga Procultura, MAFIZ is launching the fourth edition of this professional platform, which will take place from March 10 to 12, 2026. The Málaga Short Corner has established itself as a strategic space for the visibility and international circulation of short films within the framework of the festival.
IBERSHORTS: A STRATEGIC PARTNERSHIP
The Ibershorts Awards are organized by the Festival de Málaga in partnership with Festhome, with the aim of strengthening the international projection of Ibero-American short films and providing concrete tools to support their distribution.
The participation of more than 15 nominees in the Málaga Short Corner reinforces the program’s international scope and its direct connection to professional market spaces.
ONLINE MARKET AND PRIVATE SCREENINGS

In addition to their on-site participation from March 10 to 12, the 15 selected films will also be available in the Málaga Short Corner online market through Festhome TV, where accredited programmers, distributors, and industry professionals will have access to private screenings.
This digital access extends the program’s reach beyond the event dates and facilitates direct connections between filmmakers and international professionals interested in the circulation of these works.
With this dual presence, both physical and online, Ibershorts further consolidates its position within the Ibero-American professional ecosystem, connecting talent, industry, and market within a single strategic framework.
The Festival de Málaga and Festhome announce the 5 finalists of the Ibershorts Award 2026

The screening of the finalist short films of the Ibershorts Award 2026 will take place on Thursday, March 12 at 10:00 PM, at Cine Albéniz in Málaga
The Festival de Málaga, in collaboration with Festhome, announces the five finalist short films of the
Ibershorts Award 2026, an initiative dedicated to promoting and giving visibility to Ibero-American short filmmaking
through a network of partner festivals.
Five films, five countries, and five authorial voices that reflect the diversity and vitality of contemporary Ibero-American short cinema.
Finalist short films

CARLOTA (Uruguay)
Director: Cecilia Moreira Pagés
Presented by: José Ignacio International Film Festival
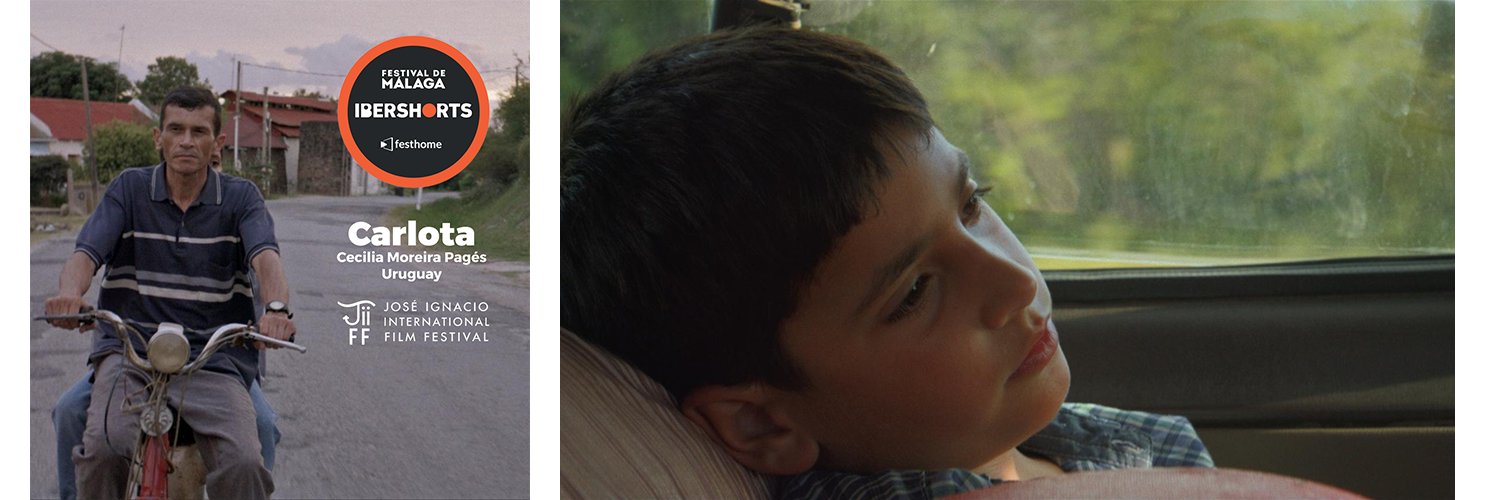
Synopsis
Miguel, a young boy from a small town in Uruguay, travels to Montevideo for the first time on a school trip. There, he discovers a portrait
of Carlota, a 19th-century historical figure, which awakens a deep fascination in him. Back home, this image turns into an obsession that
drives him to undertake an unexpected journey accompanied by Leidi.
About the director
Cecilia Moreira Pagés is a Uruguayan director and screenwriter. Her cinema is characterized by a sensitive gaze on childhood, memory, and territory.
Official film page
View here
HOW BIRDS SING (Panama)
Director: Sara Martínez
Presented by: Hayah International Film Festival of Panama

Synopsis
During an intense summer, Rafael dreams of joining his cousins at the banana plantation. Despite his grandmother’s prohibition, curiosity
and the desire for adventure lead him to disobey.
About the director
Sara Martínez is a Panamanian filmmaker. Her work focuses on childhood observation and the relationship between characters and their natural environment.
Official film page
View here
FAMILY SUNDAY (Mexico)
Director: Gerardo Del Razo
Presented by: Huesca International Film Festival

Synopsis
In a peripheral neighborhood of Mexico City, a shopkeeper faces the consequences of failing to pay a fee imposed by a criminal group.
What appears to be an ordinary Sunday turns into a test of endurance.
About the director
Gerardo Del Razo is a Mexican director and screenwriter. His cinema addresses contemporary social issues from a realistic perspective.
Official film page
View here
THE ASSISTANT (Peru)
Director: Pierre Llanos
Presented by: Skyline Benidorm Film Festival

Synopsis
Clara helps her father in an improvised dental clinic. During the lunch break, the unexpected arrival of a patient disrupts the routine.
About the director
Pierre Llanos is a Peruvian filmmaker. His work is characterized by an intimate and naturalistic approach.
Official film page
View here
SOL MINOR (Portugal)
Director: André Silva Santos
Presented by: Curtas Vila do Conde – International Film Festival

Synopsis
Samuel, a flute teacher, goes through the mourning process after the death of his wife. Between letters, flowers, and melodies, he tries
to reconnect with music and with life.
About the director
André Silva Santos is a Portuguese director associated with auteur cinema, with a strong expressive use of sound and time.
Official film page
View here
An Ibero-American network of cinema and festivals
The Ibershorts Award strengthens collaboration between festivals, filmmakers, and platforms, positioning the short film as a cultural
driving force within the Ibero-American space.
The screening of the finalist short films of the Ibershorts Award 2026 will take place on
Thursday, March 12 at 10:00 PM at the Cine Albéniz in Málaga, in a public session open to audiences as part
of the official program of the Festival de Málaga.
Tickets will be available for online purchase through the festival’s official channels.
On March 14 at 12:45 a.m., in Screen 1 of the Albéniz Cinemas, the winning short film of the Ibershorts Award 2026 will be announced.
More information about the Ibershorts Award
View here
Festhome Awards the Distribution Prize to "Queda en mí" at Ventana Sur Cortos 2025

Festhome has awarded its Distribution Prize to the Argentine short film Queda en mí, directed by Rafael Nir, within the framework of Ventana Sur and its section dedicated to Latin American short films: VS Cortos.
The prize consists of direct support for the film’s international distribution, valued at USD 400 in submission fees, which may be used to submit the short film to festivals that are part of the Festhome platform, thereby facilitating its circulation and visibility within the international festival circuit.
The film is produced by Rafael Nir and Paloma Torras, with the participation of the production companies La Casa de al lado, Oruga Cine, and Harry. It has been recognized within a space that champions the short film as a top-tier creative, industrial, and cultural format.
VS Cortos: a key platform for Latin American short films
VS Cortos is the Ventana Sur section dedicated exclusively to short films, conceived to support new voices in Latin American cinema and filmmakers who embrace this format with creative freedom and a strong authorial vision.
In its 2025 edition, the call received more than 210 works with world premiere availability from across the region, confirming that the short film not only serves as a starting point for new careers, but is also a fully established space for aesthetic and narrative exploration within contemporary cinema.
Festhome’s commitment to short film distribution
With this award, Festhome reinforces its commitment to the short film as an essential format in today’s cinema and to the active support of films throughout their international journey.
The Festhome Distribution Prize, awarded to Queda en mí, aims to strengthen the film’s festival strategy, facilitating access to international calls for entries and supporting its positioning within the global short film ecosystem.

Festival de Cine Global de Santo Domingo 2026

MOISÉS TUÑÓN CHAIRS THE GLOBAL FICTION SHORT FILM COMPETITION JURY AT THE 18TH EDITION OF THE GLOBAL FILM FESTIVAL OF SANTO DOMINGO 2026
Festhome’s director, Moisés Tuñón, took part in the 18th edition of the Global Film Festival of Santo Domingo 2026 as President of the Jury for the Global Fiction Short Film Competition, one of the international sections of the Dominican festival. The event held its 18th edition from January 28 to February 4, 2026.
Moisés Tuñón’s presence on this jury reinforces Festhome’s connection with international festivals committed to discovering new voices and promoting the global circulation of short films. According to the festival’s official pre-event information, he chaired this section alongside Marc Mejía and Sofía Jamatte.
In addition, the Global Film Festival of Santo Domingo holds accreditation from the FIAPF and is recognized in its official communication as the first festival in the Caribbean to be part of this international community, highlighting its importance within the global film landscape.
A SECTION MARKED BY NARRATIVE STRENGTH AND DIVERSITY OF PERSPECTIVES

In the Global Fiction Short Film Competition, the jury chaired by Moisés Tuñón awarded the prize to El Fin del Mundo, directed by Alessandro Mosca (Peru).
Synopsis:
Under the shadow of the Mountain, Epifanio (72) falls into a deep sleep, reliving the day he was lost forever. With the help of two children, he searches for his family when a mysterious woman shows them the path they must follow.
The jury also granted a special mention to The Third Dream, directed by Mohammadhossein Nikzad (Iran).
Synopsis:
During an interrogation, it remains unclear whether the dreamer is hiding the truth or being forced, as what has been dreamed must not be revealed.
FESTHOME, PRESENT IN KEY INTERNATIONAL FILM SPACES

Moisés Tuñón’s role as jury president in this edition highlights Festhome’s active presence in leading international film events, closely supporting festivals, filmmakers, and industry professionals. In an increasingly global context, these collaborations strengthen Festhome’s commitment to short films and to the international projection of emerging talent.
CONGRATULATIONS TO THE AWARDED FILMMAKERS
From Festhome, we congratulate Alessandro Mosca for the award given to El Fin del Mundo, as well as Mohammadhossein Nikzad for the special mention received for The Third Dream.
We also thank the Global Film Festival of Santo Domingo for the invitation and the opportunity to be part of such a significant edition, both for its international scope and for the prestige brought by its FIAPF accreditation.
Festhome Distribution Award at Cortogenia 2025

FESTHOME AWARDS EL CUENTO DE UNA NOCHE DE VERANO AT THE 26TH EDITION OF CORTOGENIA 2025
As part of the 26th edition of Cortogenia, a qualifying festival for the Goya Awards, Festhome presented the Festhome Distribution Award to El cuento de una noche de verano, directed by María Herrera. The award was presented by Elvira Landa, Festival Manager at Festhome, during the event.
A BOOST FOR SHORT FILM DISTRIBUTION
The Festhome Distribution Award was created to support the festival journey of new films, helping awarded short films expand their visibility and access new exhibition opportunities.
With this recognition, Festhome reinforces its commitment to filmmakers and to the promotion of short films, offering concrete tools to support the distribution of works with both national and international potential.

CORTOGENIA, A KEY PLATFORM FOR SPANISH SHORT FILMS
Over the years, Cortogenia has established itself as one of the most recognized platforms for the exhibition and promotion of short films in Spain. Its status as a qualifying festival for the Goya Awards strengthens its relevance within the circuit and makes each edition a valuable showcase for filmmakers, producers, and industry professionals.
For Festhome, being part of this edition through the Festhome Distribution Award means continuing to strengthen ties with festivals that are firmly committed to cinematic talent and to the growth of new voices within the audiovisual landscape.
CONGRATULATIONS TO MARÍA HERRERA AND THE ENTIRE TEAM
From Festhome, we would like to congratulate María Herrera and the entire team behind El cuento de una noche de verano on this recognition.
We will continue working to support filmmakers and to help more films find their path in festivals around the world.
Festhome Distribution Award at Notodofilmfest 2026

FESTHOME BOOSTS THE DISTRIBUTION OF FOUR SHORT FILMS AWARDED AT NOTODOFILMFEST 2026
An alliance with short films and emerging talent
At Festhome, we remain committed to supporting the journey of short films beyond their premiere. That is why we are delighted to be part of Notodofilmfest once again, one of the leading spaces for short films on the internet since its creation in 2001 by La Fábrica, based on an original idea by Javier Fesser.
The 23rd edition of Notodofilmfest
In its 23rd edition, Notodofilmfest has once again demonstrated its ability to discover new voices and connect emerging talent with the industry. As part of this collaboration, Festhome takes part in the Distribution Award, a prize that this year has recognized four short films with one year of distribution through Festhome, as well as a digital copy provided by DCPCine and two years of technical support.
The winners of the 2025 Distribution Award
The short films that won the 2025 Distribution Award were Está detrás de mí, by Yago Casariego and Nacho Monter; HAIRLINE, by Bright Martins; 20:11, by Mario Capetillo Torres; and Antitermitas, by Alex Rey. Four very different works, united by one essential quality: their potential to keep growing within the international festival circuit.
A recognition that also reaches the Grand Prize

Our involvement in Notodofilmfest does not end there. The Grand Prize for Best Film, awarded this year to fit, by María de Miguel, also includes distribution through Festhome, in addition to a cash prize of 3,000 euros and a digital copy provided by DCPCine.
Distribution as a way to extend a film’s journey
For Festhome, collaborating with festivals such as Notodofilmfest means reinforcing something that is part of our DNA: helping short films find new opportunities, new audiences, and new festivals. Because an award does not only recognize a work, it can also open new paths for it.
Congratulations to the award winners
Congratulations to the awarded short films and to the entire Notodofilmfest team for another edition that continues to celebrate talent, creativity, and the strength of the short film format.
The Ibershorts Award Launches

THE FESTIVAL DE MÁLAGA OPENS ITS PROGRAM TO IBERO-AMERICAN SHORT FILMS THROUGH THE NEW IBERSHORTS AWARD
Nearly 30 festivals from 20 countries will participate in the 29th edition of the festival through this initiative, in collaboration with Festhome.
The Festival de Málaga, organized by Málaga City Council through Málaga Procultura, has launched the new Ibershorts Award, whose first edition will take place during its 29th edition, to be held from March 6 to 15, 2026.
The complete rules and regulations are available on the festival’s official website, and submissions must be made through the Festhome platform until November 30.
A BRIDGE FOR IBERO-AMERICAN SHORT FILMS
Ibershorts is an initiative by the Festival de Málaga, in partnership with Festhome, aimed at promoting and giving visibility to Ibero-American fiction and animation short films.
This new award, which will be integrated into the festival’s official program, seeks to recognize the quality and diversity of short films produced in Ibero-American countries, including Portugal and excluding Spain.
Through this initiative, the Festival de Málaga reinforces its Ibero-American vocation and builds a network of strategic alliances with leading festivals, creating new opportunities for filmmakers and consolidating an international visibility circuit for short films.
AN INTERNATIONAL NETWORK OF QUALIFYING FESTIVALS
A total of 29 festivals from 20 countries have joined the call. Each festival may submit up to two award-winning short films from its most recent edition, which will automatically become eligible alongside other winning titles.
A joint committee appointed by the Festival de Málaga and Festhome will select five finalists, which will be screened during the festival’s 29th edition.
AWARD AND INTERNATIONAL PROJECTION
The winner of the Ibershorts Award will receive the Silver Biznaga for Best Ibero-American Fiction Short Film 2025, presented at the official short film awards gala of the festival.
In addition, the five selected short films will take part in the Málaga Short Corner, an initiative integrated within MAFIZ / Spanish Screenings Content, where they will participate in industry screenings and professional activities.
PARTICIPATING FESTIVALS IN THE IBERSHORTS AWARD

- ASUFICC - Asunción International Contemporary Film Festival (Paraguay)
- Baixada Animada - Ibero-American Animation Film Festival (Brazil)
- BITBANG International Animation Festival (Argentina)
- Ibero-American Short Film Competition Versión Española / SGAE (Spain)
- Curtas Vila do Conde - International Film Festival (Portugal)
- Curta-Se 24 Ibero-American Film Festival of Sergipe (Brazil)
- FAM - Florianópolis Audiovisual Mercosur (Brazil)
- FANTLATAM (Latin American Network)
- FENAVID - Santa Cruz International Film Festival (Bolivia)
- Gramado Film Festival (Brazil)
- Santo Domingo Global Film Festival (Dominican Republic)
- Huelva Ibero-American Film Festival (Spain)
- Cinema al Este International Film Festival (Peru)
- Cuenca International Film Festival - FICC (Ecuador)
- Huesca International Film Festival (Spain)
- Lebu International Film Festival - CINELEBU (Chile)
- Mar del Plata International Film Festival (Argentina)
- Valdivia International Film Festival (Chile)
- Kinoarte Film Festival (Brazil)
- FIC UBA - University of Buenos Aires International Film Festival (Argentina)
- FICCI - Cartagena International Film Festival (Colombia)
- Hayah - Panama International Short Film Festival (Panama)
- Ícaro - Central American International Film Festival (Central America)
- José Ignacio International Film Festival (Uruguay)
- LESGAICINEMAD (Spain)
- Pávez Awards - Talavera de la Reina International Film Festival (Spain)
- Shorts Costa Rica (Costa Rica)
- Shorts México (Mexico)
- Skyline Benidorm Film Festival (Spain)
Why submit your film with Festhome?

If you are deciding where to submit your film, you have probably come across several platforms and found yourself asking the same question many filmmakers ask: which one is the best choice for me?
At Festhome, we are clear about one thing: not all filmmakers are looking for the same thing, and not all films need the same strategy. But if budget control, security, clarity in the process, and trust in the festivals you submit to matter to you, Festhome is one of the strongest options for sending your work.
Designed for filmmakers who want to optimize their budget
We know that taking a film through the festival circuit requires a significant investment. That is why one of our goals is to help you make that investment more efficient. Festhome is especially useful for filmmakers who need to manage their resources more carefully without giving up on an international submission strategy.
Our Annual Pass and credits models help reduce the cost of using the platform and provide access to additional discounts on many submission fees. These advantages do not depend on a separate monthly subscription: they are included in the Annual Pass and in credit purchases, making it easier to build a clearer, more flexible, and more efficient strategy. Our model also allows us to pay real salaries to real people who love the world of cinema and events, people who work behind the platform checking that festivals are real, reviewing cases seriously, and providing technical support from humans, not machines.
When budget matters, every decision counts. Choosing a platform that allows you to manage your submissions clearly, without unnecessary costs and with a more transparent logic, makes a real difference.
Especially useful for independent and auteur cinema
Not all films travel the festival circuit in the same way. Some works are more commercial, while others have a more artistic, personal, or daring sensibility. In our experience, Festhome works especially well for filmmakers with an auteur, independent, or more curatorially oriented approach.
Why? Because we believe in a more thoughtful relationship between film, festival, and platform. It is not just about sending your work to as many places as possible, but about doing so with criteria and with greater trust in the ecosystem you are taking part in.
More security for you as a filmmaker
This is one of the most important points.
At Festhome, we work with festival validation protocols to reduce the risk of false, misleading, or unreliable festivals. Filmmaker safety is not an extra feature: it is a priority.
That is why, in the case of first-edition festivals, or during the first editions in which a festival uses the platform, submission fees are not paid out to the festival until its celebration is confirmed. This measure helps protect filmmakers from calls for entries that have not yet demonstrated real or consolidated activity.
In addition, we do not pay fees to festivals that do not watch the films. For us, this is essential. If a filmmaker pays a submission fee, there must be at least a minimum commitment to reviewing the work and acting seriously on the part of the festival.
These are not just defined action protocols. They are also real people reviewing cases and making real decisions. We are not perfect, but we do know that we treat our work, filmmakers, and festivals with care, and after more than a decade of experience, we know our method works very well.
Knowing whether your film has been watched changes everything
For a filmmaker, it is not enough just to submit a film. It also matters to know what happens afterward. That is why one of Festhome’s most valuable advantages is that it shows filmmakers whether their film has been watched by the festival.
This provides something very important: transparency. Because it is not the same to submit your film and remain in the dark as it is to follow the real path of your submission and know whether the festival has actually taken the time to watch your work. The same applies to showing the reality of selections, both the good and the bad, without inventing selection results.
A more reliable environment against fakes and scams

In the festival circuit, trust is essential. Every year, unclear calls for entries appear, along with festivals that do not offer real guarantees or initiatives that raise legitimate concerns among filmmakers.
That is why at Festhome we have a validation system designed to detect irregularities and prevent fakes, scams, and festivals without sufficient guarantees. Our commitment is to protect your work, your time, and your money.
We know that submitting a film is not just about uploading a file and paying a fee. It is a strategic decision. And that decision deserves to be made on a platform that takes care of you.
Closer and more human support
Another aspect many filmmakers especially value is support. At Festhome, we do not understand support as a cold form or an automated response, but as real help throughout the process.
We provide support through different channels such as phone, Instagram, or WhatsApp, which allows us to stay closer to filmmakers and better adapt to their language and level of technological familiarity. Because every filmmaker is different, and not everyone needs the same kind of help or interacts with technology in the same way.
That closeness makes support more useful, more natural, and more human. Our work is focused on helping with solutions tailored to the person asking for help, and although a machine may respond faster, our answers are always more effective because a person has taken the time to read, understand, and work on the issue.
Clarity, trust, and a cleaner experience
The submission experience should be simple, understandable, and direct. When you are managing deadlines, materials, versions, subtitles, premieres, and festival strategies, you do not need more noise: you need a clear and functional platform.
That is why we work to offer a cleaner interface, more intuitive navigation, and a more transparent relationship between filmmaker and festival. After more than 10 years, we continue improving and adapting to new technologies, enhancing our service, and aiming to be a tool that supports the work of filmmakers and festivals.
So, when should you choose Festhome?
Festhome is a great option if:
- You have a tighter budget and want to optimize your submissions.
- You want access to discounts without relying on a separate monthly subscription.
- You value knowing whether your film has been watched by the festival.
- You want stronger guarantees regarding the legitimacy of festivals.
- You care about a platform that is clear, approachable, and easy to use.
- You want to feel more protected against questionable or unreliable festivals.
- You support real people making a living and working to make this industry better.
In summary
It is not only about where you submit your film. It is about how you do it and what kind of platform accompanies you through that process.
At Festhome, we believe filmmakers should be better protected, better informed, and better supported. If you are looking for a platform that takes better care of filmmakers, Festhome is for you.
How can I know that my film has arrived correctly?
It's an excellent question, one that allows us to explain an essential part of how Festhome works, something that is just as important on this blog as anything else we've discussed in recent years.
So how can a filmmaker at Festhome be sure that his film has got where it needs to go?
First of all, a correctly made submission that is in the inbox of the corresponding festival automatically appears on the film's Statistics page (specifically, in Statistics - Submission Status).
By default, until the festival sees the inscription, a red clock appears to the right of that inscription. When the festival has seen it, that icon changes automatically and becomes a blue eye. Once the festival notification date has passed (which also appears there next to the registration) that icon changes again, and there are 3 possible changes:
-If the festival has put the entry in the Selected state, that icon becomes a white thumbs up in white on a green background.
- If the festival has not put it in Selected status, the icon becomes a white x on a gray background.
- Finally, if the festival has not worked with the registration statuses so that we can tell you if you are selected or not, our system will show you the figure of a man with a watch in white on a gray background. We do this because we want to show clearly that we don't make up submission statuses or change them capriciously, so that filmmakers know that we don't have enough information to indicate a selection or non-selection and we indicate it directly, without filters, so filmmakers know what to expect.
In any case, all you have to do is place the cursor on that icon (in any of its different options) for a tooltip to appear that tells the filmmaker what it means at all times and, therefore, what the festival is doing with the submission at any time.
That is the information that filmmakers can see every moment about the status of their submissions.
As a final note, we want to emphasize that we insist that festivals see all their entries, and especially when it comes to festivals with their own entry fee, if we detect problems with viewings from a festival, our system automatically blocks payments until are solved. Although the platform seems to be a simple internally, there is a lot of work behind it, and we take it very seriously that all parties involved, filmmakers and festivals, are satisfied with our role as intermediaries. If we detect festivals that are not fulfilling their part of seeing and evaluating their entries, we do not hesitate to contact them and resolve it.
OYSTERS AND SNAILS
Naturally you may like only oysters or only snails, but it is much more enriching to enjoy both knowing that they are different, and therefore being able to see with as much joy the science fiction made in Hollywood in the 50s and the essays of the Dziga Vertov Group in the 60s/70s, knowing that they are different things. And we should be thankful for that, because there is not one single type of cinema that has been possible in 120 years, and counting, of cinematographic history.

Incident with our servers

What happened?
Around 2 AM, all Festhome services became inaccessible. After a quick evaluation, we realised that the problem came from the main database server, on which the rest of the services rely to save and obtain the data pertaining to everything that is done in Festhome. Once the data center operators could physically access the server in question, they informed us that the hard drive was not working, so we started the process to recover the data from another hard drive and replace the failed one to put back the online service. This in itself is not a very big problem, and apart from the time lost without connection, which at this moment was a little over an hour, there would be no further incident. The serious problem arouse when accessing the second disk that contains the instant backups, as it did not respond either. From this moment on, we started working on trying to recover the data from the hard drives so that we could restore service with all the data, but hours go by without much progress and finding more and more problems with the hard drives. We believed that some kind of power outage or something similar had fried both hard drives at the same time, since it is extremely rare for two hard drives to die at the same time. In these 13 years we have never lost a single piece of information or registration and we are very ashamed of this episode.
What did we do?
Once the magnitude of the problem was known, we decided to work in parallel on using one of the backups external to the server to restore the service if we were not able to recover it with the data from the failed server. About 7 hours after the start of the incident, we had the service ready to be restored, but with the data from the last backup that was made external to the server, which is from Thursday morning, the 20th.
At this point, we had to make the decision to wait to recover the data from the corrupted hard drives so that there are no lost shipments or transactions, or to restore service without Thursday's data. After careful consideration, we decided that too many hours had passed without service, and it was important that users could continue to send and watch the movies, and whenever we had he data for Thursday, we would push it back to the new server manually.
This seemed to be the right decision, as several days later we are still trying to recover the other server, but we have less and less hope that we can indeed recover the data that was not saved on other servers.
What solutions have we found for now and the future?
Right now, our support colleagues have been manually rebuilding transactions that users have told us they lost, but it's an imperfect solution. We count on our users to notify us of problems they have had, to manually fix those problems and have all the data as it should appear in their accounts. It's a slow process, but right now it seems to be the only one possible.
As for the future, we're going to increase the redundancy of the databases in the live service with better point-of-failure protections, so that if a server suddenly fails, the service will continue to function. 13 years is a long time without losing data, but if we can be better, we must be, so we are also going to increase the frequency of external back-ups to the data servers, in case there is a similar problem in the future, we can recover data with less loss.
We want to apologise to all our users and thank you for your enormous patience in recent days. It has been many hours without sleep and with great nerves due to ignorance of what was happening. When you have a computer in front of you, it's already difficult at times but at least you can touch it. With servers hosted in bunkers thousands of kilometers away and with which you can only work with a Matrix-style command line, uncertainties and nerves increase exponentially.
EVERY YEAR WITH 13 MOONS
If Fassbinder is essential it is because no one (or almost) like him was able to x-ray and show how human relationships are based on possession and the natural cruelty that possession entails, and he did so by creating films that were sometimes cruel, sometimes failed, but always stark, honest and lucid, like that impossible proof of love in In a Year with 13 Moons, or that imaginary happiness in Fox and His Friends. Perhaps the forgetfulness I mentioned above is due to the fact that the bulk of his filmography (an astonishing number of 44 works between feature films for cinema and television, some short films, some miniseries, some macroseries, all made in a time frame of just 15 years) can be described as melodramas, a genre reviled in our days for reasons that elude me, and that Fassbinder learned to love and practice by watching the very remarkable work of another forgotten master, Douglas Sirk. Or perhaps the cause of it is the fact that Fassbinder's work lacks the handbrake, the self-censoring and the sugar coating of contemporary drama.
Be that as it may, it is never a bad time, with or without an anniversary, to remember and celebrate the work of the Bavarian genius, and to declare (contrary to what the title of his first feature film affirms) that the love for Fassbinder's work can never be colder than death.

THE SHORT FILM’S LONG REACH
If we talk about short films as cinematographic works, we must remember that some of the great masters in the history of cinema have delivered great works in short format (Godard, Malle, Varda, Marker, Garrel ...). As a work of art, short film is already recognized throughout the world. But is it as an industrial product?
Following the logic of capitalism, a short film can never produce the same profit as a feature film (in fact, it is unusual for a short film to generate a profit), whether its budget is very large or very small, so as an industrial product it will never have the same recognition as a feature film, naturally, and it would be rather healthy to understand that these two perspectives are complementary and do not exclude one another.

FROM BERLANGA TO EL FARY
Without genuflection, but on his knees, López Vázquez’ character represents several generations of men at the mercy of power, fame, feminine beauty understood as a platonic ideal, and who have a very evident exponent in El Fary when he spoke of the "soft man" without realizing he was also subjugated. The violence defended by people like El Fary only showed their impotence and in 2022 we are grateful because they are disappearing, although gender violence has not, sadly, been extinguished yet.

UNSUNG HEROES
Schoonmaker has not worked alone for Scorsese, but almost, and it becomes so difficult to find in a film made by another director the continuation of the movement by cut (movement of the camera or the elements / people in the shot) that is so natural and frequent in the cinema of the filmmakers from New York, that one tends to think that Scorsese films for Schoonmaker, and that Schoonmaker determines the way he shoots.

THE PARADOX OF PURITANISM

I don't think we can and should not excuse John Ford for those behaviors, neither in the 30s/40/50s nor now in 2022. But neither can we ignore them, as if they were acceptable, nor cancel John Ford entirely, as if we hope that great creators should not have serious character flaws. What we can do is assume the natural imperfection of the human condition, accept John Ford as a great creator with terrible flaws that should never be silenced, and appreciate his films to a greater or lesser extent. It's easy to say, very hard to do.